About This Project
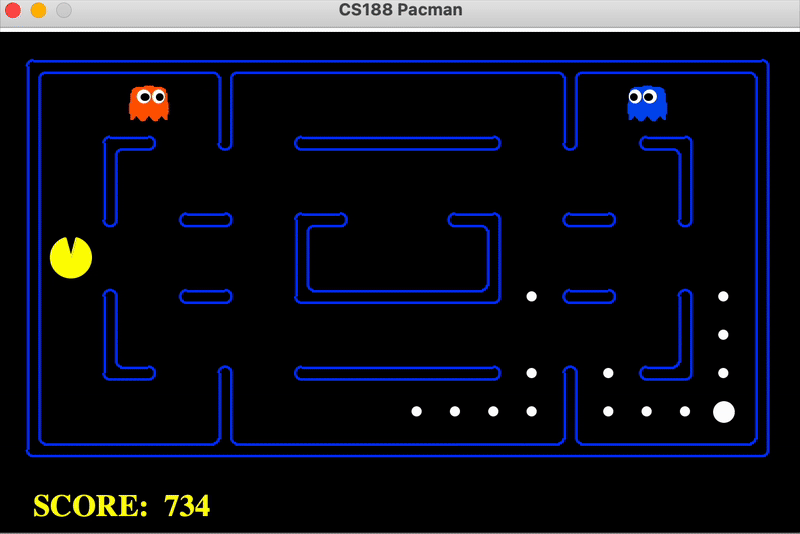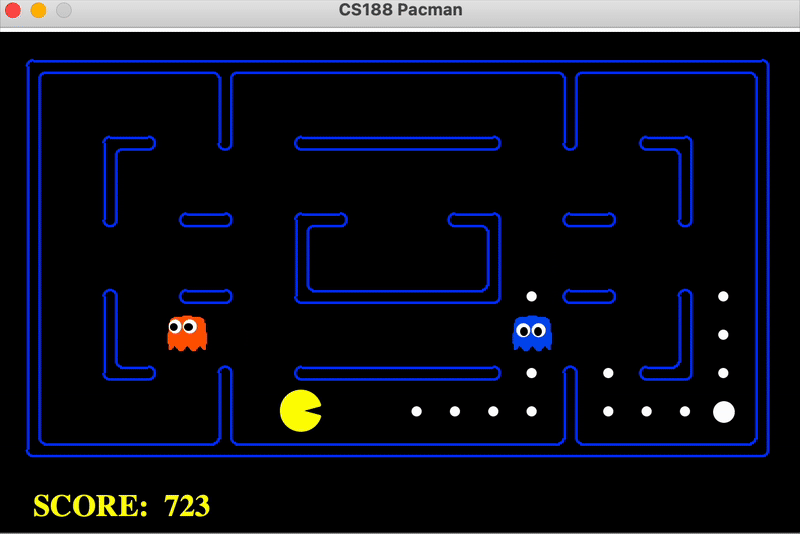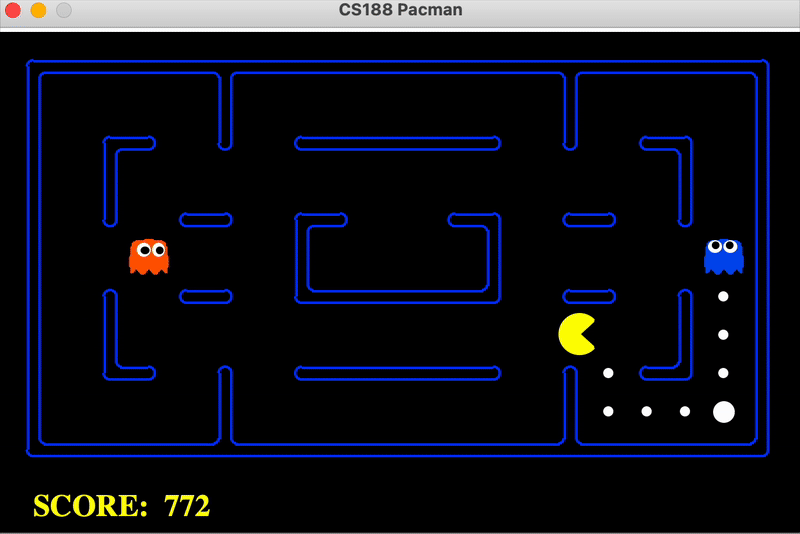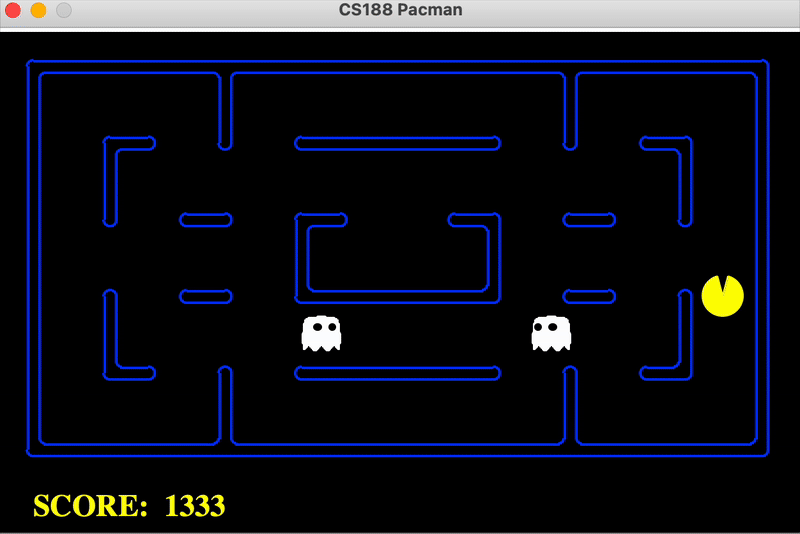
Implemented Value Iteration and Q-learning agents for policy optimization tasks. Experimented with discount factors, noise, and living rewards to analyze agent behavior in environments such as Pacman and bridge crossing. Developed Epsilon-Greedy exploration and Approximate Q-learning for scalability.
Key Features
- Q-learning implementation
- Policy evaluation and control
- Exploration with epsilon-greedy
- Approximate Q-learning for scalability